SIMILAR: Submodular Information Measures Based Active Learning In Realistic Scenarios
[Accepted to NeurIPS 2021- Paper, Code]
Over the past several years, active learning (AL) strategies have proven to be useful in reducing labeling costs. However, current methods do not work well when it comes to real-world datasets, which have imperfections and a number of characteristics that make learning from them challenging:
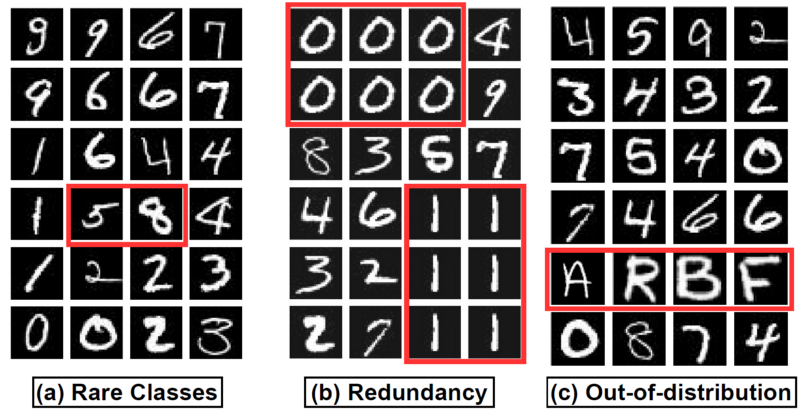
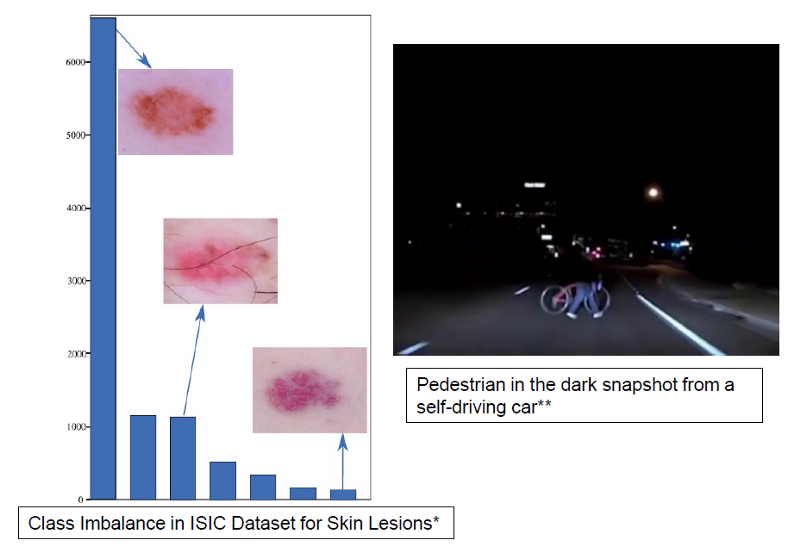
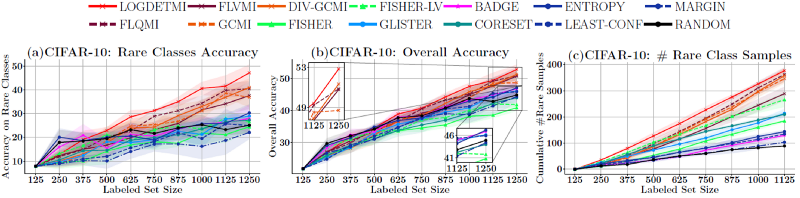
Firstly, real-world datasets are imbalanced and some classes are very rare. Some examples of this imbalance come from medical imaging domains; for instance, images of cancer cells are often rarer than their benign counterparts in cancer imaging datasets. Another example is in the domain of autonomous vehicles, where we want to detect all objects accurately. However, because some objects in certain situations are rare, like pedestrians in the dark, it is often the case that these models fail in detecting and classifying rare classes.
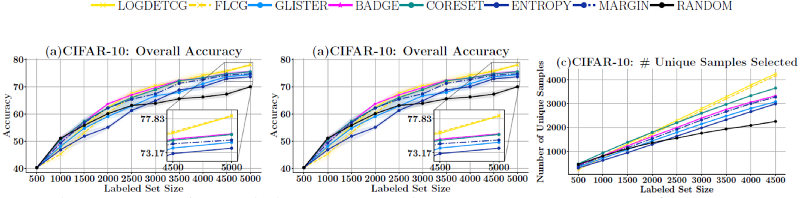
Secondly, real-world data has a lot of redundancy. This redundancy is more prominent in datasets that are created by sampling frames from videos (e.g., footage from a car driving on a freeway or surveillance camera footage).

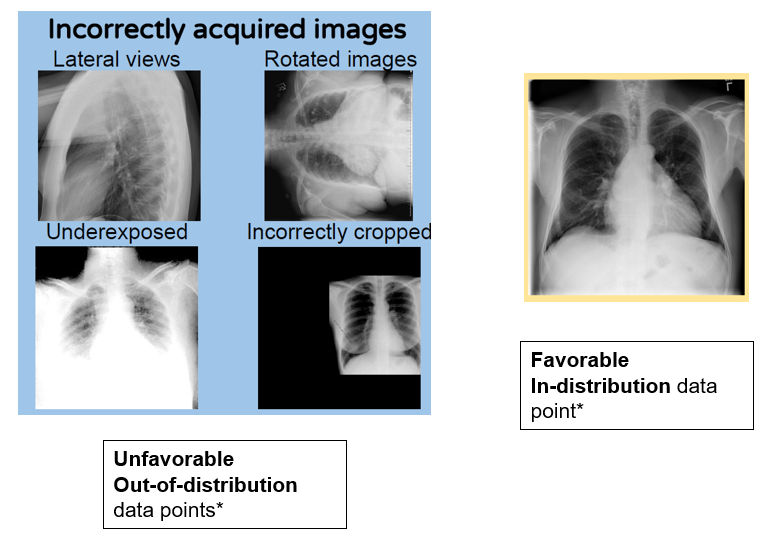
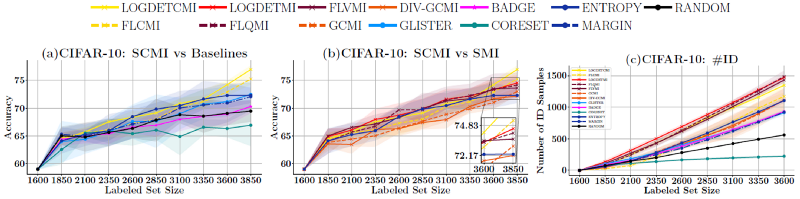
Thirdly, it is common to have out-of-distribution (OOD) data, where some part of the unlabeled data is not of concern to the task at hand. For example, in the medical imaging domain, some X-ray images in the dataset may be incorrectly acquired, thereby making them out-of-distribution.
In our work, we address the following question:
Can a machine learning model be trained using a single unified active learning framework that works for a broad spectrum of realistic scenarios?
**The SIMILAR framework
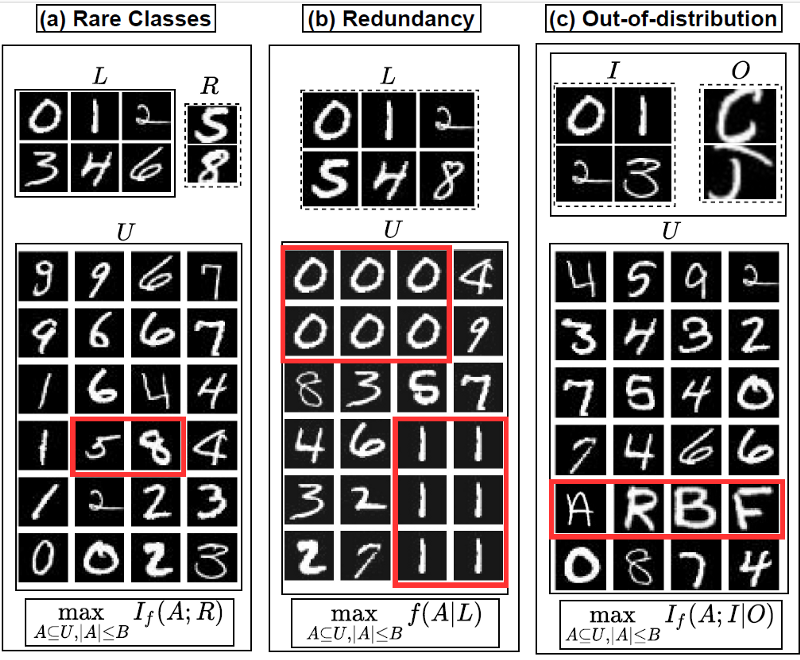
**We propose SIMILAR, a unified active learning framework that acts as a one-stop solution for many realistic scenarios discussed above. The main idea behind our framework is to exploit the relationship between the submodular information measures (SIM) by appropriately choosing a query set Q and a private set P. The unification comes from the rich modeling capacity of submodular conditional mutual information (SCMI). We obtain the submodular mutual information (SMI) and submodular conditional gain (SCG) formulations from SCMI and apply them to different realistic scenarios.

We use the last linear layer gradients using hypothesized labels to represent each data point. The hypothesized label for each data point is assigned as the class with the maximum probability. To instantiate the SIM based functions, we compute a similarity kernel using the gradients of the model obtained from the current active learning round. Finally, we optimize the submodular function using a greedy strategy to acquire a subset of the unlabeled set for human labeling. Once labeled, we add it to the labeled training dataset and proceed to the next iteration.
In the above example for real-world dataset scenarios for digit classification, we can apply the SIMILAR framework as follows.
Results
Empirically, we show that SIMILAR significantly outperforms existing active learning algorithms by as much as ≈ 5% − 18% in the case of rare classes and ≈ 5% − 10% in the case of out-of-distribution data on several image classification tasks like CIFAR-10, MNIST, and ImageNet.
SIMILAR is available as a part of the DISTIL toolkit: https://github.com/decile-team/distil
To make using SIMILAR easy, we provide tutorial notebooks for each of the realistic scenarios discussed above:
- Rare Classes Tutorial on CIFAR-10
- Rare Classes Tutorial on Medical Data
- Redundancy Tutorial
- Out-of-distribution data Tutorial
Future Thoughts We believe that SIMILAR is a promising step in the direction of active learning for realistic scenarios. The main limitation of our work is the dependence on good representations to compute similarity. In the future, we also look forward to approaches that can be used in cases where the characteristics of the dataset are completely unknown.
Author Suraj Kothawade