RETRIEVE: Coreset Selection for Efficient and Robust Semi-Supervised Learning
[Accepted to NeurIPS 2021- Paper, Code]
Summary
We propose RETRIEVE, a coreset selection framework that selects a subset of unlabeled data by solving a mixed discrete-continuous bi-level optimization problem to efficiently train the models on the selected subset using the existing state-of-the-art semi-supervised algorithms like VAT (Miyato et al., 2019), Mean Teacher (Tarvainen & Valpola, 2017), FixMatch (Sohn et al., 2020). We further empirically demonstrate that using RETRIEVE enables faster model convergence and a 3x training speed up by training on the informative unlabeled subsets. Furthermore, RETRIEVE achieves a 5x speedup compared to state-of-the-art (SOTA) robust SSL algorithms in the case of unlabeled data with class imbalance and out-of-distribution (OOD) data.
Introduction
In recent years, semi-supervised learning(SSL) algorithms have shown remarkable success in limited labeled data regimes. For example, a recent SSL algorithm FixMatch (Sohn et al., 2020) demonstrated that using just 250 labeled examples, we can train a Wide ResNet-28–2 (Zagoruyko & Komodakis, 2016) model that achieves a test accuracy of around 95% on the CIFAR10 dataset.
Despite the success of the current SOTA SSL algorithms, they are extremely computationally intensive and require significant training times. For instance, from our experience, training a WideResNet-28–2 (Zagoruyko & Komodakis, 2016) model on a CIFAR10 dataset with 4000 labels using the SOTA FixMatch (Sohn et al., 2020) algorithm for 500000 iterations takes around four days on a single RTX2080Ti GPU. The increased training time also implies increased energy consumption and an associated carbon footprint (Strubell et al., 2019). Furthermore, it is common to tune these SSL algorithms over a large set of hyper-parameters, which means that the training needs to be done hundreds and sometimes thousands of times. Below is an image, showing the compute costs of SSL algorithm FixMatch (Sohn et al., 2020) along with hyperparameter tuning.

SSL’s significant compute costs make it difficult to extend semi-supervised learning research at most universities and smaller companies. The first problem that we try address in RETRIEVE is:
Can we efficiently train a semi-supervised learning model on coresets of unlabeled data to achieve faster convergence and reduction in training time?
Furthermore, SSL algorithms enable us to achieve similar performance to supervised learning models by making better use of unlabeled data. However, in most real-life scenarios, the unlabeled data is directly mined from web sources. The relative ease of acquiring unlabeled data from web sources makes it very easy to accrue some out-of-distribution (OOD) examples or achieve an uneven representation of unlabeled samples belonging to different classes.
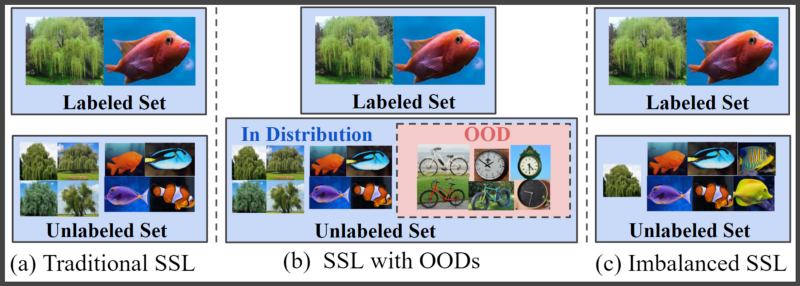
Despite demonstrating encouraging results on standard and clean datasets, current SSL algorithms perform poorly when OOD data or class imbalance is present in the unlabeled set (Oliver et al., 2018, Chen et al., 2019). Several recent works (Chen et al., 2019, Guo et al., 2020) were proposed to mitigate the effect of OOD in unlabeled data, in turn improving the performance of SSL algorithms. However, the current SOTA robust SSL method called DS3L (Guo et al., 2020) is almost 3X slower than the standard SSL algorithms, further increasing the training times, energy costs, and CO2 emissions. The second problem that we try to address in RETRIEVE is:
In the case where OOD data or class imbalance exists in the unlabeled set, can we robustly train an SSL model on coresets of unlabeled data to achieve similar performance to existing robust SSL methods while being significantly faster?
RETRIEVE addresses the problems mentioned above by selecting informative coresets of unlabeled data that enable faster convergence and robust training of SSL algorithms. Specifically, RETRIEVE selects a coreset of the unlabeled data resulting in minimal labeled set loss when trained in a semi-supervised manner. In the Robust SSL scenario setting, RETRIEVE minimizes the loss of clean validation set instead of the labeled set loss. Intuitively, RETRIEVE tries to achieve faster convergence by selecting data instances from the unlabeled set whose gradients are aligned with the gradients of the labeled set examples. RETRIEVE also achieves distribution matching between the unlabeled coreset and the labeled set used for training by selecting an unlabeled coreset whose gradients are maximally aligned with the gradients of the labeled set.
Semi-supervised learning problem formulation
Given a labeled set D with n labeled data points, an unlabeled set U with m data points and a model with parameters θ, the loss function for many existing SSL algorithms can be written as:
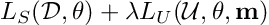
where λ is the regularization coefficient for the unlabeled set loss. For Mean Teacher, VAT, MixMatch, the mask vector m is made up entirely of ones, whereas for FixMatch, m is confidence-thresholded binary vector, indicating whether to include an unlabeled data instance or not. Usually, the labeled set loss is cross-entropy loss for classification experiments and squared loss for regression experiments.
RETRIEVE Framework
In RETRIEVE, the coreset selection and classifier model learning on the selected coreset is performed in conjunction. Further, RETRIEVE is an adaptive coreset selection framework, i.e., the unlabeled coreset selected by RETRIEVE changes as the model training progress, and the newly selected unlabeled coreset is used for subsequent training of the semi-supervised model.

As shown in the pipeline figure, RETRIEVE trains the classifier model on the previously selected coreset for R epochs in a semi-supervised manner, and every R epochs, a new coreset is selected, and the process is repeated until the classifier model reaches convergence, or the required number of epochs is reached. Hence, as the model training progresses, the quality of the coreset selected by RETRIEVE improves.
RETRIEVE’s problem formulation
The coreset selection problem of RETRIEVE for classifier model parameters θ is given as follows:

In the above equation, the outer level of the above optimization problem is a discrete subset selection problem. However, solving the inner-optimization problem naively is computationally intractable, and we need to make some approximations for efficiently solving the above optimization problem.
To solve the inner optimization problem efficiently, RETRIEVE adopts a one-step gradient approximation based optimization method similar to MAML (Finn et al., 2017). More specifically, RETRIEVE approximates the solution to the inner level problem by taking a single gradient step towards the descent direction of the loss function. The idea here is to jointly optimize the model parameters and the subset as the learning proceeds. After this approximation, the coreset selection optimization problem becomes:
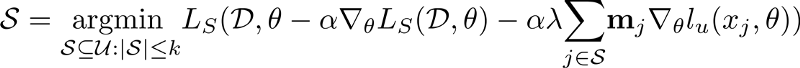
However, the optimization problem above is NP-hard, even if the labeled set loss is convex loss. We can convert the above optimization problem as a maximization problem by multiplying it with -1. The resulting maximization problem can be written as follows:
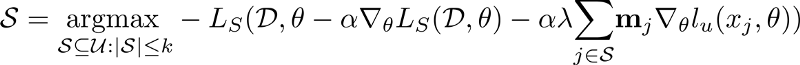
Furthermore, If the labeled set loss function is cross-entropy loss, then the optimization problem given in above equation is an instance of cardinality constrained weakly submodular maximization problem.
This implies that the optimization problem given in the above equation can be solved efficiently using greedy algorithms (Minoux, 1978) with approximation guarantees. RETRIEVE uses an accelerated version of a lazy greedy algorithm called a stochastic-greedy algorithm (Mirzasoleiman et al., 2015) to solve the optimization problem given in the above equation.
To solve the optimization problem given in the equation above, we need to calculate the loss over the entire labeled set multiple times for each greedy iteration, making the entire greedy selection algorithm computationally expensive. Hence, to make the greedy selection algorithm efficient, we approximate the above equation by using the first two terms of it’s Taylor-series expansion. The resulting optimization problem solved at each greedy iteration after Taylor-series approximation can be given as follows:
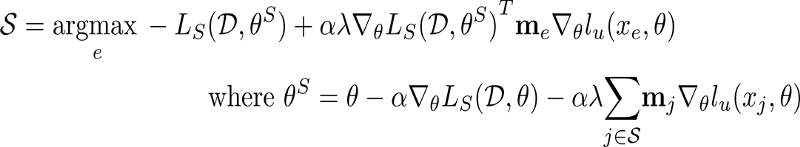
In the above equation, S is the current subset, and at every greedy iteration, an element with the maximal dot product value between the currently labeled set loss gradient and the unlabeled element e loss gradient is selected and added to the existing subset S.
Implementation Aspects
To further speed up coreset selection, RETRIEVE considers some modifications to the above optimization problem during implementation, such as using only last layer gradients for coreset selection and selecting subset every 20 epochs. RETRIEVE also considers warm starting the model by training it on the entire unlabeled set for a few epochs so that the coresets selected by RETRIEVE are informative and not random. Please find the entire implementation details of RETRIEVE and the detailed pseudocode of the coreset selection algorithm in the paper (Killamsetty et al., 2021).
Results
a. Performance of RETRIEVE in Traditional SSL scenario:
In the traditional SSL scenario, we compare the accuracy-efficiency tradeoff achieved by RETRIEVE with different subset selection approaches like CRAIG, Random. We compare the performance for different subset sizes of the unlabeled data: 10%, 20%, and 30% and for three representative SSL algorithms VAT, Mean-Teacher, and FixMatch.
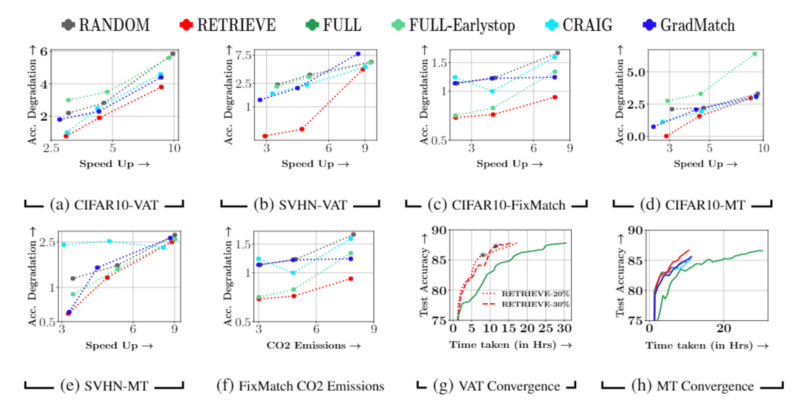
The above results shows the comparison of RETRIEVE with baselines RANDOM, CRAIG, FULL, Full-EarlyStop in the traditional SSL setting. Speed Up vs Accuracy Degradation, both compared to the original SSL algorithm used were shown in the above image for VAT on CIFAR-10 in the sub-plot (a), VAT on SVHN in the sub-plot (b), FixMatch on CIFAR-10 in the sub-plot ©, MT on CIFAR-10 in the sub-plot (d), and MT on SVHN in the sub-plot (e). The results given above shows that RETRIEVE significantly outperforms existing baselines in terms of accuracy degradation and speedup tradeoff compared to SSL. Sub-plot (f) of the above image also compares the CO2 emissions among the different approaches for FixMatch SSL algorithm, showing again that RETRIEVE achieves the best energy-accuracy tradeoff. At the same time, sub-plots (g) and (h) are the convergence result plots comparing accuracy with the time taken. Again, RETRIEVE achieves much faster convergence than all baselines and full training.
b. Performance of RETRIEVE in Robust SSL scenario:
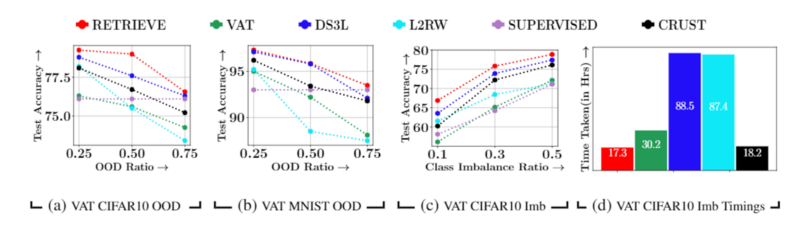
We test the performance of RETRIEVE on CIFAR10 and MNIST datasets with OOD in the unlabeled set and CIFAR10 dataset with the class imbalance in both labeled and unlabeled sets. Sub-plots (a)(b) of the image given above show the accuracy plots of RETRIEVE for different OOD ratios of 25%, 50%, and 75%. The results show that RETRIEVE with VAT outperforms all other baselines, including DS3L (Guo et al., 2020), a state-of-the-art robust SSL baseline in the OOD scenario. Next, sub-plot © shows the accuracy plots of RETRIEVE for different class imbalance ratios of 10%, 30%, and 50% on the CIFAR-10 dataset. The results show that RETRIEVE with VAT outperforms all other baselines, including DS3L (Guo et al., 2020) (also run with VAT) in the class imbalance scenario. In particular, RETRIEVE outperforms other baselines by at least 1.5% on the CIFAR-10 with imbalance. Sub-plot (d) shows the time taken by different algorithms on the CIFAR10 dataset with a 50% class imbalance ratio. The results show that CRUST (Mirzasoleiman et al., 2020) did not perform well in terms of accuracy and speedups achieved compared to RETRIEVE. Except for MixUP, CRUST is similar to CRAIG, which did not perform well than RETRIEVE in the traditional SSL setting. Furthermore, the performance gain due to MixUP for coreset selection in the SSL setting is minimal. The minimal gain can be attributed to the fact that the hypothesized labels used for MixUP in the earlier stages of training are noisy.
Furthermore, as stated earlier, CRUST was developed to tackle noisy labels in a supervised learning setting and is not developed to deal with OOD or Class Imbalance in general. The results show that RETRIEVE is more efficient compared to the other baselines. In particular, RETRIEVE is 5x times faster compared to the DS3L method.
Results Summary:
Specifically, we see that in the traditional SSL setting, RETRIEVE consistently achieves close to 3x speedup with accuracy degradation of around 0.7%. RETRIEVE also achieves more than 4.2x speedup with a slightly higher accuracy degradation. Furthermore, when RETRIEVE is trained for more iterations, it can match the performance of original SSL algorithms while having a 2x speedup. RETRIEVE also consistently outperforms simple baselines like early stopping and random sampling in the traditional SSL setting.
In the robust SSL setting, we further demonstrate the utility of RETRIEVE in the presence of OOD data and imbalance in the unlabeled set. We observe that with the VAT as SSL algorithm, RETRIEVE outperforms SOTA robust SSL method DS3L (Guo et al., 2020) (also run with VAT) while being around 5x faster. RETRIEVE also significantly outperforms just VAT and random sampling in the robust SSL setting.
Conclusion
This blog post introduced RETRIEVE, a discrete-continuous bi-level optimization-based coreset selection method for efficient and robust semi-supervised learning. In my opinion, the application of subset selection approaches for efficient learning is an area of research with tremendous potential. Because the reduced training times that subset selection strategies can achieve help reduce carbon footprint and training costs, getting us closer to Green AI (Schwartz et al., 2020). To that extent, RETRIEVE acts as a POC(proof of concept) to demonstrate the potential speed-ups and energy savings that can be achieved for existing SSL algorithms (specifically robust SSL algorithms) by simply training on informative unlabeled subsets.
Author
CARAML LAB